Vocalizations and speech
Vocalizations and speech
One of the key functions of the human auditory system is of course to allow us to exchange ideas through speech. Human speech seems to be unique in its sophistication, but many animals use vocal communication to a greater or lesser extent. Chapter 4 of "Auditory Neuroscience" looks at the encoding and processing of vocalizations, and speech sounds in the central nervous system. The following pages provide supplementary material on this topic.
Hoover the talking seal
Hoover the talking seal
Although there are differences (some would argue important differences) in the details, the vocal tracts of other mammals are fundamentally similar to those of humans. Some mammals are able to use these similarities to mimic human voices. An example is "Hoover the talking seal", an orphaned harbour seal who was raised by a fisherman and started mimicking the sound of the burly voice of his adoptive father. Hoover's "speech" (sound sample below) is somewhat slurred, but the words "come over here" and "hurry" are nevertheless clearly audible.
Another rather endearing example of a "speaking mammal" can be seen on the next page, which features Mishka the talking dog.
One reason why we find such examples striking is that they are rather unusual, and even the most gifted talking seal or dog would struggle to keep up a meaningful conversation for any length of time. How much we can learn about human speech from studying animal vocalizations is a hotly debated and controversial topic.

Mishka, the talking dog
Mishka, the talking dog
This youtube video shows a husky dog named "Mishka", exchanging some surprisingly verbal declarations of love with her owners.
Speech as a "modulated signal"
Speech as a "modulated signal"
Speech, like many interesting, natural sounds, is a dynamic signal, i.e. its amplitude and frequency content change over time. One interesting question asked by Elliott & Theunissen is whether speech has "characteristic" time varying amplitude and frequency distributions. Do the "temporal and spectral modulations" of speech have to follow within certain parameter ranges for speech to be comprehensible or recognizable? What temporal and spectral modulations does speech normally exhibit? And are there particular modulations that are "necessary" to make speech identifiable or comprehensible?
Elliot and Theunissen addressed this question by calculating the "modulation spectra" of speech as shown here:
Such modulation spectra are "inveritble", meaning that (provided you are skilled at digital signal processing) you can go from the modulation spectrum back to the original sound, possibly after removing certain ranges of modulation from the original signal, and you can then ask whether the speech sounds remain comprehensible if particular modulations are removed.
Here some examples. First an original speech sound:
Now the same speech sample with all temporal and spectral modulations filtered out except for the "core" region with spectral modulations of less than 4 cycles/kHz and temporal modulations between 1 and 7 Hz. The sample remains comprehensible but sounds very artificial.
An interesting result from this decomposition into spectral and temporal modulations is that the "meaning" of speech sample "lives in a different part of modulation space" from voice pitch or speaker identity.
Consider this example where all temporal modulations are preserved, but all only spectral modulations below 0.5 cycles / kHz are preserved. This preserves speech formants, so the speech remains comprehensible, but pitch information is mostly lost and we can no longer tell whether it is a male or female speaker:
And compare this against a sample where all temporal modulations faster than 3 Hz are filtered out. Now we are missing the time structure important for carrying "meaning", and the sentence becomes harder to understand, but we can still easily identify the voice pitch and gender of the speaker:
The Role of Pitch in Speech
The Role of Pitch in Speech
In Indo-European languages, changing the pitch of the voice usually does not change the meaning of a spoken word or sentence. We illustrate this here, using as our speech sample one of the finer samples of political rhetoric of the early 3rd millennium. (No, not Obama, Bush. Dubya asserting that peace with fish is possible, which is of course enormously reassuring.) In addition to the original speech sample, we add two further samples which have been processed with Hideki Hawakara's "Straight" software, which can decompose speech into its pitch and formant contours, and resynthesize it after the pitch contour has been altered. The result sounds remarkably realistic. So here, then, is Bush, pleading for peace with fish, first normal, then with a steadily rising, and then with a falling pitch contour. You will note that, after the pitch manipulation, the speech remains comprehensible (at least, it is no less comprehensible than it was on the outset).

Bush pleads peace with fish. (Original pitch contour, varying between about 110 and 200 Hz)
Bush pleads peace with fish, rising pitch. (Steady, linear rise from 80 to 350 Hz)
Bush pleads peace with fish, falling pitch. (Steady, linear fall from 350 to 80 Hz)
In the examples above we manipulated the pitch of the speech to rise or fall over a widerange, which had no appreciable effect on how comprehensible the sentences are. This may create the impression that voice pitch is unimportant in spoken English, but that would be only partly true. While in English, voice pitch has no "semantic" role, it is a key feature of "prosody", which can, for example, give us non-verbal cues to a speaker's intent or affect. To illustrate this, consider the next two examples where we took the pitch contour of the original recording, and then either halved or doubled the range of the pitch variation. When the pitch range is halved, the voice sounds markedly depressed, when it is doubled it sounds very excited.
Bush depressed. (Normal pitch contour compressed from normal 110 - 200 Hz range to a much smaller 110-120 Hz range)
Bush excited. (Normal pitch contour expanded from normal 110 - 200 Hz range to a much larger 50-350 Hz range)
Human vocal folds in action - youtube video
Human vocal folds in action - youtube video
Human speech sounds come in two flavors: voiced and unvoiced. Voiced speech sounds are generated when the vocal folds produce a rapid click train, the so called "glottal pulse train", which then resonates around the vocal tract. This youtube video of a human laryngoscopy procedures shows the vibrating vocal folds during vocalization. Note the muscular apparatus which can open the vocal folds wide when the subject takes a deep breath, or vary the amount of tension on them to change the voice pitch.
Human Articulators in Action - Video
Human Articulators in Action - Video
This movie is from the website of the Speech Production and Knowledge Group (SPAN) at the University of Southern California.
It shows the vocal tract of a young lady, imaged with magnetic resonance technology, while she talks about her love of music. You can clearly see the tongue, lips and jaw moving, as well as the soft palate rising and falling, which dynamically changes the resonant properties of the vocal tract, imposing a "time-varying formant structure" onto the speech signal.
Formants and harmonics in spoken vowels
Formants and harmonics in spoken vowels
This figure (fig 1.16 of "Auditory Neuroscience") shows spectrograms of the words "hot", "hat", "hit" & "head" spoken once with a high-pitched voice (top), and then again with a lower pitched voice (bottom). You can see that the vowels of the speech sounds are made up of regularly spaced harmonics (the red stripes) which originate from the glottal pulse train and determine the pitch of the spoken word. You can also see that the harmonics are not all of equal intensity. For example, the vowel /a/ has more energy at ca 1.8 kHz than either the /o/ or the /i/. Regions of frequency space where speech sounds carry a lot of energy are known as "formants", and these formants arise from resonances in the vocal tract. Speakers change the resonance frequencies by moving their "articulators" (lips, jaws, tongue, soft palate), and thereby changing the dimensions of the resonance cavities in the vocal tract.
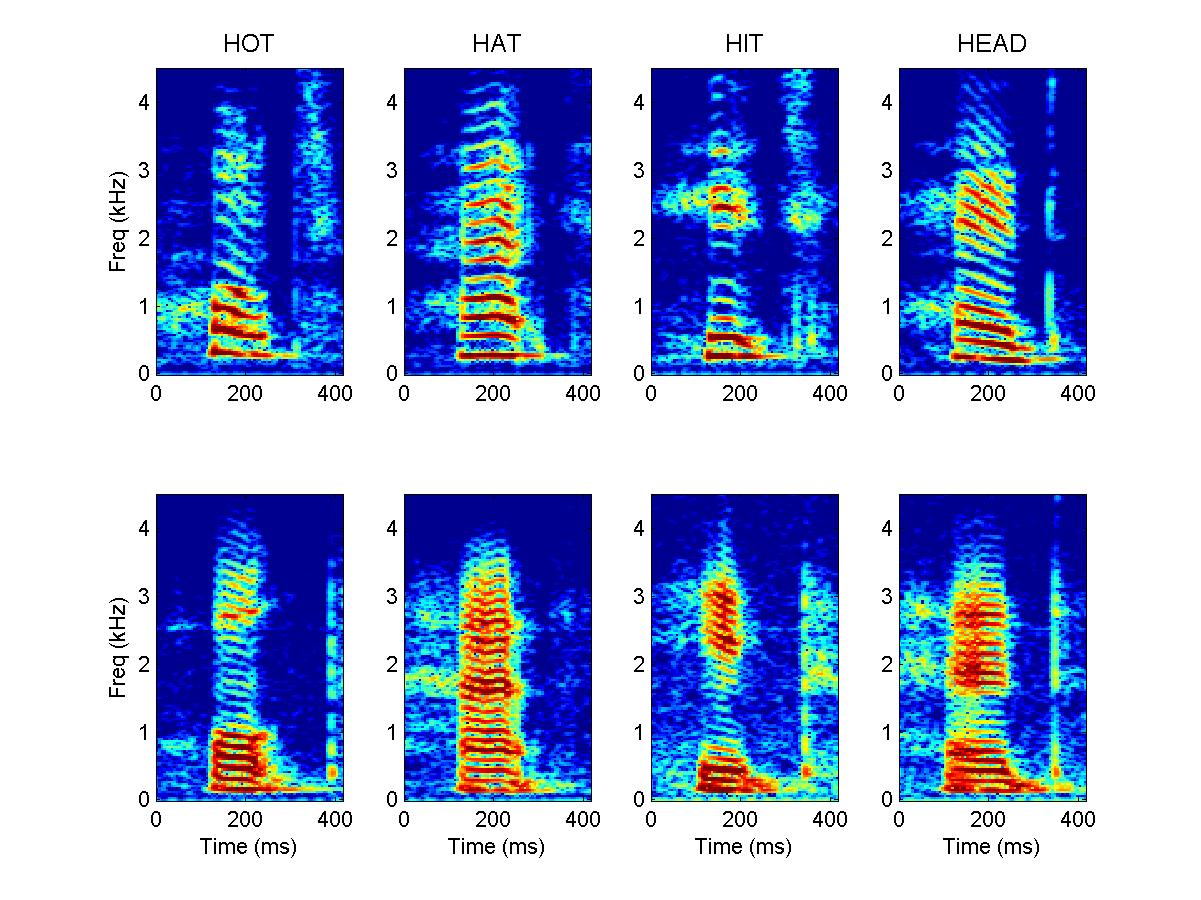
High Pitched Voice
Low Pitched Voice
Source: full color version of Figure 1-16 of "Auditory Neuroscience"
Two Formant Artificial Vowels
Two Formant Artificial Vowels
A little interactive demo to illustrate the role formants play in vowel sounds.
Local time reversal and speech comprehension
Local time reversal and speech comprehension
It is widely appreciated that, when speech is time reversed, it becomes incomprehensible but it continues to sound rather speech-like, not unlike the sound of a foreign language. However, as was discovered by Saberi and Perrott in 1999, if speech is cut into small strips and each strip is short enough, then speech does remain comprehensible. The sound examples on this page illustrate this effect. The sounds reversed in 200 or 100 ms wide strips are normally completely incomprehensible, while with 50 ms wide strips some listeners start to understand the odd word, and a time reversal of 20 ms wide strips does not affect comprehension at all.

200 ms time reversal
100 ms time reversal
50 ms time reversal
20 ms time reversal
original
Looking for brain areas that extract meaning from speech with spectrally rotated sounds
Looking for brain areas that extract meaning from speech with spectrally rotated sounds
Sophie Scott and colleagues tried to identify areas in the brain that might be involved in mapping sound to meaning using a neuroimaging approach. They used speech samples which they either vocoded , so they sounded different but were still comprehensible, or they "rotated" the speech to make it incomprehensible while keeping it "acoustically similar" to normal speech. They then calculated contrasts to work out which areas were more strongly activated by one type of stimulus rather than another. Only the area shown in yellow on the left anterior temporal lobe showed significantly stronger activation by comprehensible when compared to incomprehensible speech samples.
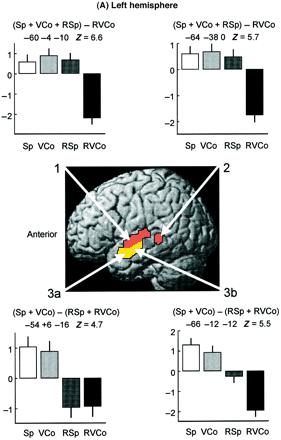
(Sp=speech, VCo=vocoded speech, RSp=rotated speech, RVCo= rotated vocoded speech).
If you are curious how spectrally rotated speech sounds like, listen to the examples below. (My gratitude to Stuart Rosen for letting me have his spectral rotation algorithm, and to George W. Bush for being such an endless fount of utterances which illustrate that the distinction between comprehensible and incomprehensible speech is, well, shall we say "nuanced".)
Original speech
Spectrally rotated speech
Broca's Aphasia - videos
Broca's Aphasia - videos
This video from the archives of the University of Wisconsin at Madison Physiology department shows an interview with a patient with Broca's aphasia. The patient has great difficulty articulating sentences, and produces only isolated words and utterances. However, note that his utterances are "on topic", suggesting that he has little difficulty understanding the speech of his interviewer. This difficulty in articulation rather than comprehension has led to Broca's aphasia being described as a "motor aphasia".
Broca's aphasia is usually associated with lesions to Broca's area, an area of the prefrontal cortex which the French neurologist Paul Broca had found to be damaged in his very severely aphasic patient Mr Leborgne, nicknamed "Tan tan" because he was unable to utter anything other than "tan, tan, tan..." This image shows Mr Leborgne's brain, which is now preserved in a museum in Paris.
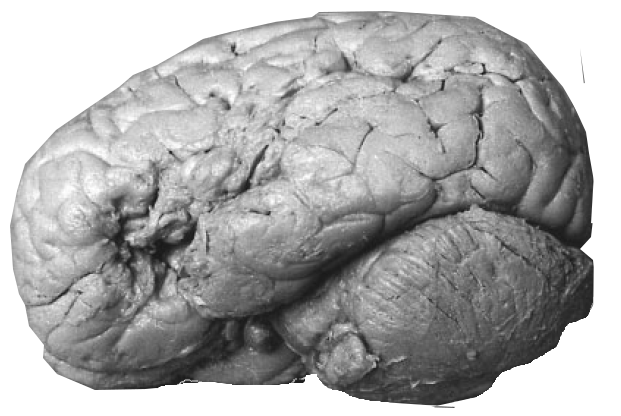
Although Broca's area is thought of as a motor aphasia, brain imaging studies suggest that this area is often also activated when we are listening to speech.
Here another, more recent video showing the teenage aphasia patient Sarah Scott. Note how Sarah sometimes uses written words to help herself. Nevertheless, it is not uncommon for Broca's aphasia patients to have difficulties producing written as well as spoken language.
Wernicke's Aphasia
Wernicke's Aphasia
Another video from the archives of the University of Wisconsin at Madison Physiology department shows an interview with a patient with Wernicke's aphasia. Unlike patients with Broca's aphasia, Wernicke's aphasics tend to speak fluently, but their speech often degenerates into seemingly random, very hard to follow "streams of consciousness", which may be peppered with non-words or made up words. Also, the speech of Wernicke's aphasics often fails to provide good answers to questions posed to them, suggesting that they do not really understand the speech of their interviewers. This difficulty in comprehension rather than articulation has led to Wernicke's aphasia being described as a "receptive aphasia".
Wernicke's aphasia is usually associated with lesions to "Wernicke's area", a piece of cortical tissue at the boundary between the parietal and temporal lobes.
The McGurk Effect
The McGurk Effect
The "McGurk Effect" illustrates that what our eyes see can influence what we hear. The video here below shows Prof Patricia Kuhl's demonstration of this effect. She is mouthing the syllables /ga-ga/, but the video has been dubbed with a sound track of her saying /ba-ba/. Your eyes can tell that the lips are not closed at the beginning of the syllables, and they therefore tell your brain that the syllable cannot be /ba/, even though in reality it is. Trying to reconcile the conflicting information from your eyes and ears, the brain will decide that the syllables are those that is acoustically closest to /ba-ba/ which are articulated with the lips open, and you will "hear" /da-da/ or /tha-tha/. Howver, if you play the video again, but close your eyes, you will be able to convince yourself that the sound track is really /ba-ba/. Play it over and over, and open and close your eyes at random. The sound you hear will flip from /tha-tha/ to /ba-ba/ depending on whether your eyes are open or not.